„Die Erkenntnis aus Daten ist im Bereich der Energiewirtschaft – wie auch in vielen anderen Industriezweigen – das zentrale Thema der Zukunft und bietet mit das größte Potenzial für künftige Geschäftsmodelle“, konstatiert Christopher Schemm, Deputy Director Transportation & Energy bei Infoteam Software. Viele Systemanbieter und Komponentenhersteller würden sich deshalb derzeit massiv mit den Möglichkeiten der neuen digitalen Welt entlang der energiewirtschaftlichen Wertschöpfungskette beschäftigen, so Schemm.
Gerade hier stehen grundsätzlich eine Vielzahl völlig unterschiedlicher Datenquellen zur Verfügung, sodass sich ebenso unterschiedliche Anwendungsszenarien daraus ableiten lassen, wie die nachfolgende exemplarische Aufzählung zeigt.
Netzbetreiber können über verschiedene Kanäle wie Nutzeranalysen mittels Smart Metering, Daten aus der Einspeisung oder externe Informationen wie Wetterdaten Rückschlüsse auf die Auslastung ihrer Stromnetze und die demografische Verteilung der Stromkunden ziehen – dezidiert entschlüsselt nach Tageszeit und Region oder Haushalt. Mit diesem Wissen ließen sich beispielsweise zielgruppenangepasste Produkte und Services anbieten.
Die Analyse von Verbraucherverhalten ermöglicht es, Systeme beispielsweise hinsichtlich der Usability oder der angebotenen Aufgaben zu optimieren. Nutzen etwa Stromkunden bestimmte Angebote oder Funktionen nicht oder kommt es zu auffälligen Anwendungsfehlern, so lassen sich diese Informationen gezielt für erweiterte Services, Updates und/oder neue Software nutzen. Ähnliches gilt auch für die Softwaresysteme, mit denen Kundendienstmitarbeiter arbeiten.
Ein Ausfall von Stromnetzkomponenten, Teilbereichen oder ganzen Stromnetzen lässt sich vorhersagen. So können sie rechtzeitig überprüft und Defekte behoben werden. Neben der zugrunde liegenden Analyse solcher Betriebsdaten ist auch die Übertragung großer Datenmengen eine Herausforderung. Edge-Computing ist ein dafür geeignetes Verfahren, bei dem die Daten direkt auf der überwachten Komponente vorverarbeitet, komprimiert und gegebenenfalls sogar schon analysiert werden. Infolgedessen müssen nur noch die wenigen relevanten Datenpakete ganz gezielt an übergeordnete Analysedatenbanken gesendet werden, wodurch sich die benötigte Datenbandbreite deutlich reduzieren lässt.
Predictive Maintenance in der Energietechnik
„Für die meisten Data-Analytics- und somit auch für Predictive-Maintenance-Anwendungen ist ein individuell auf die Kundendaten abgestimmtes mathematisches Modell die richtige Vorgehensweise“, erklärt Christopher Schemm. Dabei gibt es zwei unterschiedliche Herangehensweisen: Der eine Lösungsweg ist der Top-down-Ansatz, also der Einsatz vorgefertigter Frameworks mit beschränkten und von vornherein festgelegten Algorithmen. Hierbei ist darauf zu achten, dass die vorhandene Datenquelle auch mit dem Framework kompatibel ist. Der andere Lösungsweg ist der Bottom-up-Ansatz, also eine individuell entwickelte Lösung, die präzise auf die konkrete Fragestellung des Kunden zugeschnitten ist und dafür passgenau und flexibel die Werkzeuge nutzt, die auf die Anforderungen ideal passen. Um zusammen mit dem Kunden die für ihn beste Lösung entwickeln zu können, durchlaufen unsere Projekte üblicherweise die folgenden Schritte:
Schritt 1: Datensammlung und Datenerhaltung
Viele Unternehmen speichern bereits seit geraumer Zeit eine Vielzahl von Daten ab. Das ist insbesondere für Predictive-Maintenance-Anwendungen ein wichtiger Punkt, denn hierfür werden sogenannte historische Daten benötigt: Die mathematischen Modelle „lernen“ im zweiten Schritt aus den Komponentenausfällen der Vergangenheit und können das Erlernte auf aktuelle Daten anwenden. In solchen Fällen ist die Art der Datensammlung bereits etabliert und die Datenhaltung technologisch gesetzt.
Ein Großteil dieser Daten wird heute jedoch noch gar nicht für tiefgreifende Analysen genutzt. Um dies zu ermöglichen, müssten sie zunächst systematisch aufbereitet werden. Liegen beispielsweise Daten in unterschiedlichen Formaten vor, müssen sie erst zur weiteren Verarbeitung automatisiert ausgelesen und in eine Datenbank eingefügt werden. Besteht der erste Schritt darin, eine Datenhaltung aufzubauen. Es gibt eine Vielzahl an Übertragungswegen für Daten und eine Vielzahl von Datenbanken und Möglichkeiten, Daten zu halten – darunter geläufige Namen wie Apache Hadoop, diverse NoSQL-Datenbanken wie MongoDB oder Apache Cassandra sowie klassische SQL-Datenbanken. Welche Daten, welche Übertragungswege und welche Datenhaltung tatsächlich die beste Lösung darstellt, richtet sich nach dem gewünschten Nutzen, den der Kunde mit seinen Daten erzielen möchte. Sollen allerdings große Datenpakete schnell gespeichert, analysiert und abrufbar sein, so etablieren sich in jüngster Zeit Data Vault 2.0 mit massiv-parallelen Datenbanklösungen und Data Lake.
Schritt 2: Die iterative Modellerstellung
Um zielführende Datenanalysen starten zu können, ist im Vorfeld die gewünschte Fragestellung möglichst präzise herauszuarbeiten. Hier gilt: je spezieller die Frage, desto detaillierter und zielführender das Ergebnis. Dabei ist die Zusammenarbeit von Data Scientists mit Experten der jeweiligen Domäne ein wichtiger Schlüssel zum Projekterfolg. In der Energietechnik könnte zum Beispiel eine Frage lauten: „Lässt sich anhand bestimmter gesammelter Sensordaten die Lebensdauer einer Stromnetzkomponente vorhersagen?“
Um die Lebensdauer einer bestimmten Komponente vorherzusagen, sind die bereits erwähnten historischen Daten notwendig. Anhand dieser „lernt“ und „erkennt“ das mathematische Modell Zusammenhänge innerhalb der Daten, die in der Vergangenheit zu einem Ausfall der Komponente geführt haben.
Hierfür gibt es verschiedene Modelle des maschinellen Lernens, etwa Entscheidungsbäume, Support Vektor Machines oder Gradienten-Boosting-Verfahren. Ebenfalls sind Kombinationen von Modellen, sogenannte Ensembles, vielversprechende Methoden. Die hinsichtlich Datenumfang als auch Komplexität aufwendigsten Modelle sind neuronale Netze. Ihr Einsatz erfordert neben viel Erfahrung auch höchste analytische Exaktheit, da bei falscher Handhabung ein hohes Maß an falschen Voraussagen existiert. Im Gegenzug bieten aber neuronale Netze bei der professionellen Anwendung und ausreichend großer Datenbasis auch das größte Potenzial für präzisen Informationsgewinn. Das entstandene ausgereifte mathematische Modell lässt sich auf Live-Sensordaten anwenden, um dann auf der Basis historischer Erfahrungen mögliche zukünftige Komponentenausfälle vorhersagen zu können.
Schritt 3: Automatisierte Prozesse
Im Hinblick auf das Beispiel, bei dem die restliche Lebensdauer einer Stromnetzkomponente prognostiziert werden sollte, kann für ein ausgereiftes Modell nun eine Grenze definiert werden, ab der automatisiert ein festgelegter Prozess angestoßen wird. Das kann von Warnmeldungen über automatisierte Handlungsaufträge für Servicetechniker bis hin zu automatisch ausgelösten Bestellvorgängen von Ersatzteilen reichen. Hierfür müssen die Kompetenzen aus domänenspezifischem Prozesswissen, Data Science und softwaregestützter Automatisierung vereint werden.
Dank der transparenten Vorgehensweise zur Planung und Budgetierung von Ersatzmaßnahmen können Servicetechniker rechtzeitig mit den vorgehaltenen Ersatzteilen die Reparatur vornehmen. Dies geschieht dann bevorzugt nachts, wenn der Stromverbrauch der Haushalte sehr niedrig ist und damit geringere Auswirkungen auf deren Tagesablauf hat. Anderenfalls lassen sich Abschaltungen von Stromnetzen aber zumindest besser planen, sodass parallele Stromnetze zugeschaltet werden können, die den Ausfall abfedern und die Verbraucher im besten Fall den Ausfall gar nicht wahrnehmen.
Das gilt auch im Hinblick auf häufig vernachlässigte Usability-Aspekte der von den Endanwendern genutzten Applikationen. Die Entwicklung von Predictive-Maintenance-Applikationen ist folglich kein in sich geschlossener Prozess, sondern ein Zusammenspiel mehrerer komplexer Disziplinen, und setzt Erfahrung in all diesen Bereichen voraus.
Zusatzinformationen: Maschinelles Lernen
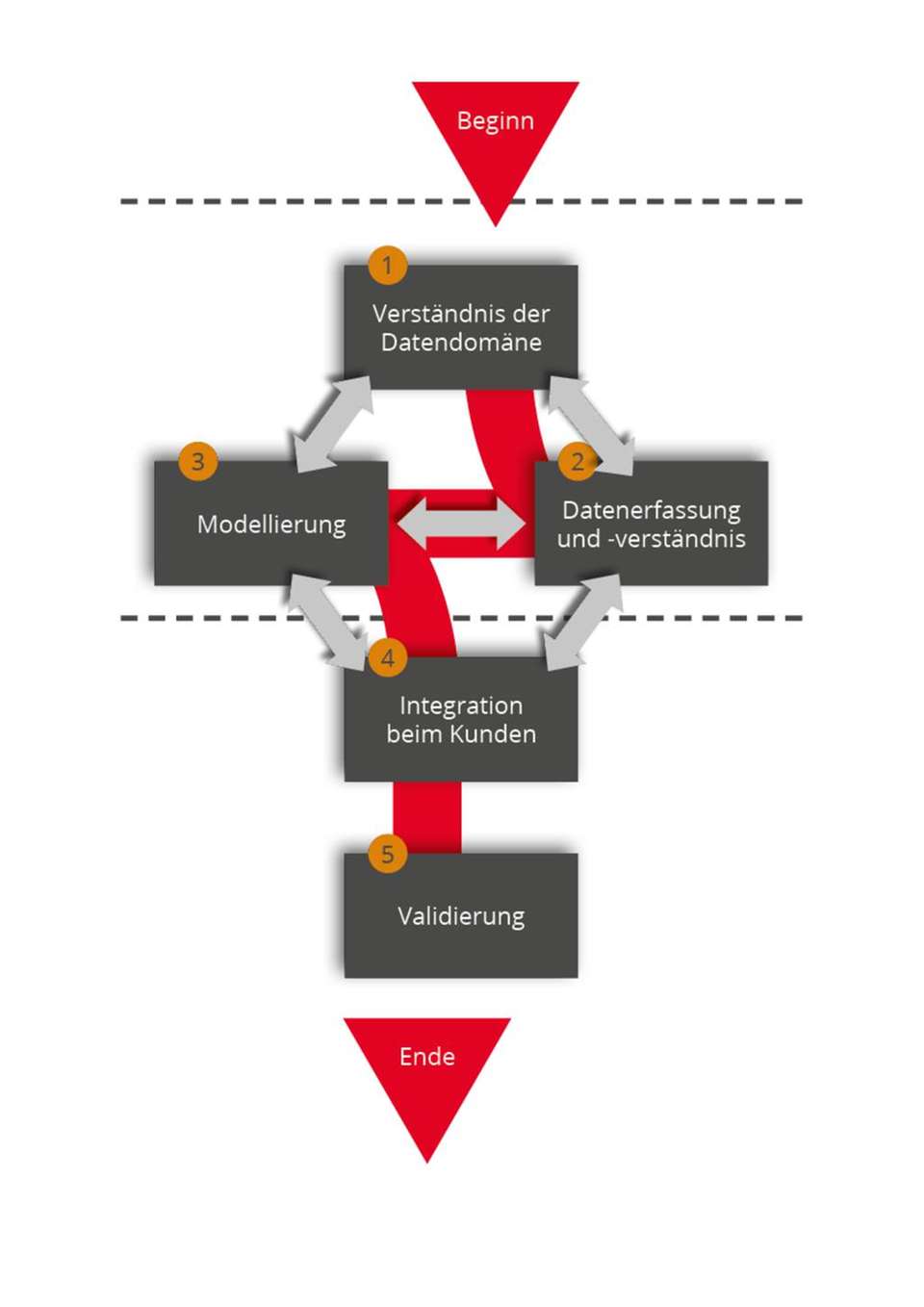
Die Entwicklung eines Modells des maschinellen Lernens ist ein iterativer Prozess. Die einzelnen Iterationen bestehen aus mehreren Schritten, die sich so lange wiederholen, bis der gewünschte Reifegrad des Modells erreicht ist. Hierfür gibt es unterschiedliche Data-Science-Entwicklungsprozesse. Einer der besten ist der Team Data Science Process (TDSP), den Microsoft entwickelt hat und kontinuierlich gepflegt wird. Neben einer standardisierten Projektstruktur liefert der TDSP auch eine Definition des Lebenszyklus und bietet sich für den Einsatz agiler Projektmanagementmethoden an.
Der TDSP sorgt im ersten Schritt für ein gemeinsames, datenbezogenes Verständnis zusammen mit dem Kunden. Anschließend werden die Daten einer ersten Ist-Analyse als Vorbereitung für die nachfolgende Modellierung unterzogen. Mit der Modellierung startet gleichzeitig auch der Abgleich des Modells mit dem zu Beginn festgelegten Verständnis der Datendomäne. So gewinnt das Modell sukzessive an Qualität. Mit dem Erreichen des gewünschten Reifegrads wird das fertige Modell innerhalb der IT-Struktur des Kunden eingebettet und arbeitet von da an in der Produktivumgebung (Live-System) mit aktuellen Daten. Parallel dazu kann im Hintergrund das Modell weiterhin verfeinert werden.