Oftmals werden die Begriffe Machine Learning (ML) und Künstliche Intelligenz vermischt; es gibt allerdings Unterschiede. So befasst sich das Themenfeld der KI generell mit dem Nachbilden der menschlichen Intelligenz. ML kann hingegen als Teilbereich der KI angesehen werden, in dem Computern das Lernen von Zusammenhängen beigebracht werden soll, anstatt sie fest zu programmieren. Wie beim Data Mining liegt der Ursprung des Machine Learning in der Statistik.
Im Consumer-Bereich werden ML-Technologien bereits für zahlreiche Anwendungen verwendet. Beispielsweise bauen Produktempfehlungen beim Online-Shopping, die Aufdeckung von Kreditkartenbetrug oder die Erkennung des Fingerabdrucks beim Entsperren des Smartphones auf Machine Learning auf. Die Vorgehensweise erweist sich dabei stets als ähnlich: Große Datenmengen – etwa zum Kaufverhalten des Kunden – werden aufbereitet und einem ML-Algorithmus zur Verfügung gestellt, damit sich dieser ein Modell der Daten aneignet.
Der Algorithmus lernt die Daten jedoch nicht einfach auswendig, sondern extrahiert Gesetzmäßigkeiten und Muster. Denn ein Modell, das die Lerndaten perfekt wiedergibt, versagt meist, wenn es nach der Lernphase Vorhersagen für zukünftige Daten treffen soll.
Zunehmend schwierigere Entwicklung von Expertensystemen
In der Automation verbreitet sich die Nutzung von Machine Learning zunehmend. Die häufigsten Einsatzfälle sind nichts Neues: Condition Monitoring (CM) und Predictive Maintenance (PM). Schon seit vielen Jahren findet eine datenbasierte Zustandsüberwachung und vorbeugende Wartung von Maschinen und Anlagen statt. Die Maßnahmen zielen immer auf die Erhöhung der Gesamteffektivität sowie die Vermeidung von Produktionsausfällen und Qualitätsminderung ab.
Derzeit werden in der Mehrzahl der Fälle Expertensysteme eingesetzt, bei denen der Anwender zum Beispiel Alarmschwellwerte für bestimmte Betriebsparameter einstellt oder betriebsstundenabhängige Wartungspläne für die Komponenten generiert. Aufgrund der ständig steigenden Komplexität zeigen sich der Entwurf und die effiziente Gestaltung solcher Systeme allerdings als zunehmend schwieriger. Zudem sollen Wartungen heute nicht mehr nur nach einem vordefinierten Plan durchgeführt werden, sondern bedarfsorientiert.
Die stetig wachsende Komplexität und Vernetzung der Maschinen im Rahmen von Industrie 4.0 bringen aber auch Vorteile mit sich: Daten. Die Daten der Sensoren, Aktoren und Prozessparameter, die sowieso zum Steuern des Prozesses benötigt werden, liegen zur weiteren Verwendung vor. Ergänzend können zusätzliche Sensoren verbaut werden, um beispielsweise Schwingungen von bestimmten Komponenten zu erfassen.
Diese Daten bilden nun die Grundlage für ML-Technologien. So kann mit Daten aus dem Normalbetrieb der Anlage ein Modell gelernt werden, das sich mit deren Livedaten vergleichen lässt. Treten Abweichungen vom Modell auf, deutet das zum Beispiel auf Anomalien im Fertigungsprozess hin oder zeigt Verschleiß an.
Darüber hinaus ist es möglich, spezielle Fehlerbilder in den Lerndaten zu beschriften, sodass sie frühzeitig erkannt werden. Durch diese dedizierte Vorgehensweise entfällt die manuelle und zeitaufwendige Programmierung von komplexen Regeln und Algorithmen.
Aufwendige Vorverarbeitung der Daten
Damit sich Machine Learning erfolgreich anwenden lässt, müssen einige Voraussetzungen erfüllt sein. Hier geht es zum einen um die Problemdefinition: Was genau soll getan werden? Je detaillierter der Use Case beschrieben ist, desto bessere Ergebnisse erhält der Anwender. Zum anderen muss er sich Gedanken über die Daten machen. Ihre schiere Menge ist nicht alles; vielmehr spielen die Aussagekraft über den gewählten Use Case und die Qualität eine entscheidende Rolle.
Zur Datenqualität gehören Indikatoren wie der Umfang an fehlenden Werten, die Synchronisation verschiedener Datenquellen sowie die Genauigkeit von Zeitstempeln. In der Praxis stehen Daten oft in unterschiedlichen Systemen und Formaten zur Verfügung. Sie müssen vorverarbeitet werden, um sie einem ML-Algorithmus verständlich zu machen. Dabei handelt es sich in der Regel um den aufwendigsten Teil beim Einsatz von Machine Learning.
ML ist folglich kein Allheilmittel, da ein gelerntes Modell immer nur so gut ist wie die Daten, die während der Lernphase genutzt wurden. Ferner fehlt dem Modell ein tieferes Verständnis der Daten und des Use Cases. Ob seine Aussagen deshalb sinnvoll und zuverlässig sind, muss vom Menschen gründlich evaluiert werden, bevor das gelernte Modell in die produktive Anwendung geht. Vor diesem Hintergrund ist die Zusammenarbeit von Data Scientist und Fachexperten unerlässlich.
Verarbeitung durch Edge Computing ermöglicht schnellere Reaktionszeiten
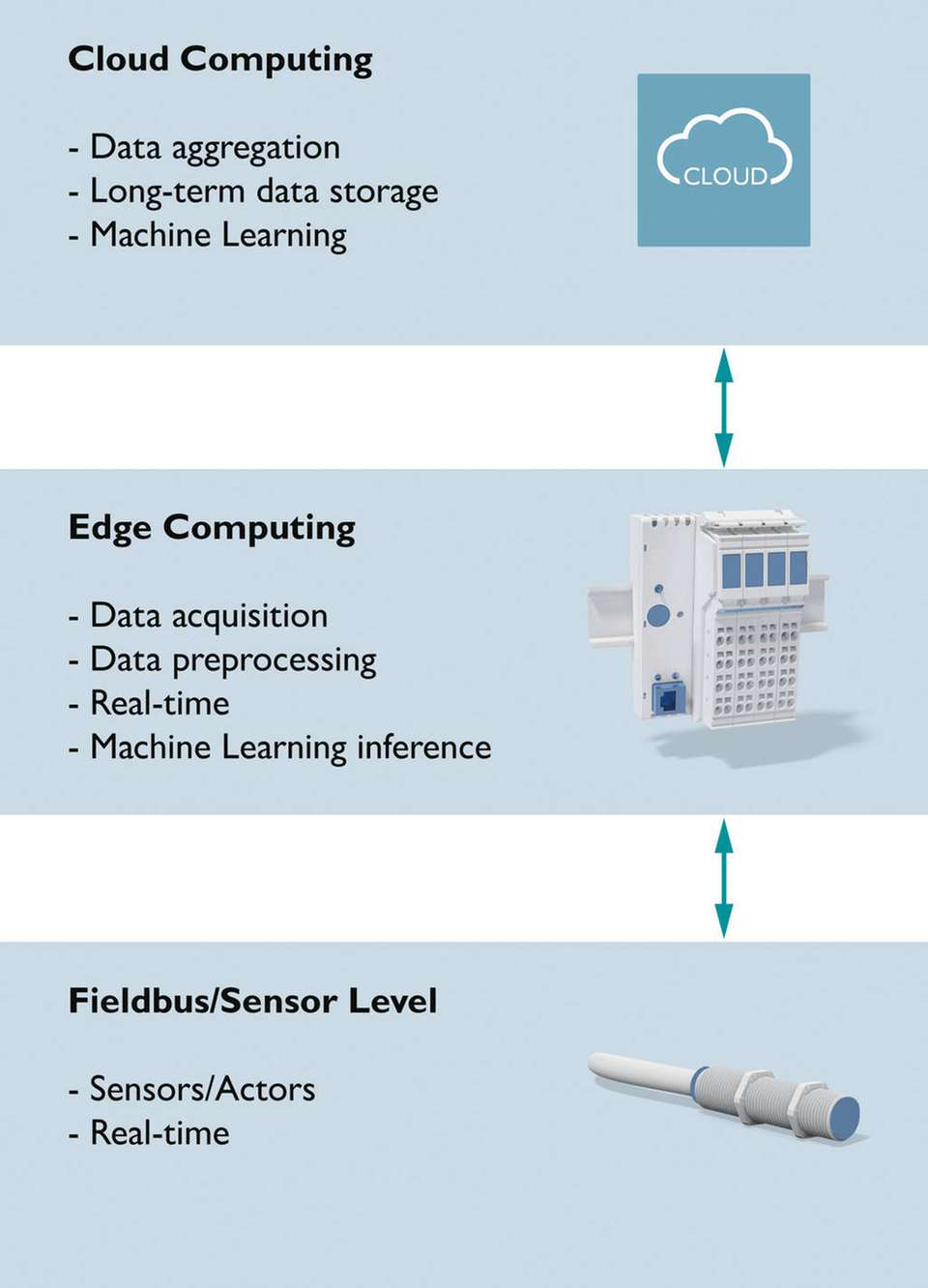
Abgesehen von der Auswahl der Daten und den verwendeten Modellen ergeben sich je nach Use Case verschiedene Anforderungen an das Deployment der Modelle. Hier stellt sich schnell die Frage, ob sich Cloud Computing oder Edge Computing als die optimale Herangehensweise erweist.
Häufig ist es sinnvoll, die Stärken von beiden Ansätzen zu nutzen. Über die Cloud lassen sich die Daten von Feldgeräten erfassen sowie langfristig und einheitlich abspeichern. Für das Lernen von Modellen werden große Datenmengen und viel Rechenleistung benötigt. Die Cloud kann die erforderlichen Ressourcen bereitstellen sowie auch Daten von weltweit verteilten Feldgeräten aggregieren und so eine sehr breite Datenbasis liefern.
Nach dem Lernen folgt das Deployment, also die Verwendung des Modells. Dies kann in der Cloud erfolgen. Doch je nach Anforderung zeigt sich das Edge Computing ebenfalls als vorteilhaft. Im Vergleich zum Lernen bedingt der Einsatz (Inferenz) des Modells „on the edge“ nur wenig Rechenleistung. Daher kann das Modell ebenso in auf der Feldebene installierten Geräten genutzt werden.
Weil der Kommunikationsweg wegfällt, lassen sich schnelle Reaktionszeiten realisieren, die mit der Cloud nicht erreichbar sind. Daten müssen somit nicht vom Gerät in die Cloud übertragen, dort eine Inferenz durchgeführt und das Ergebnis dann zurück an das Gerät transferiert werden.
Mit Edge Computing ist es außerdem möglich, die Daten bereits im Gerät vorzuverarbeiten oder beim Ausfall der Internetverbindung zu puffern. Wenn das Modell schon im Gerät läuft, können lediglich seine Ergebnisse in die Cloud kommuniziert werden. Auf diese Weise reduziert sich die Datenmenge, die in die Cloud geschickt wird, erheblich, was besonders bei Internetverbindungen über Mobilfunknetze interessant ist. Die Kombination von Cloud Computing und Edge Computing bringt folglich die meisten Vorteile.
Sukzessive Verfeinerung der Use Cases
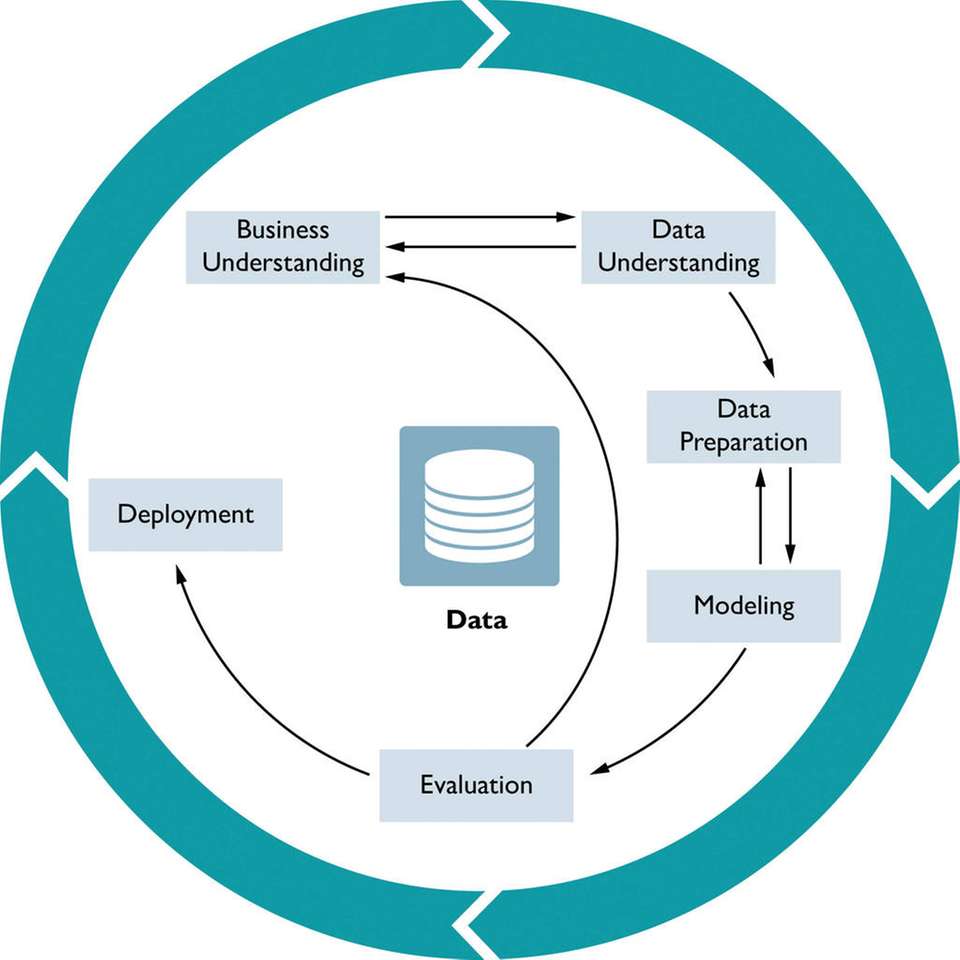
Um Use Cases erfolgreich umzusetzen, ist ein iterativer Ansatz insbesondere beim Einstieg in ML oft der beste Weg. Im Data-Science-Bereich gibt es hier einige Prozessmodelle, wie den Cross-Industry Standard Process for Data Mining (CRISP-DM) und dessen Erweiterung Analytics Solutions Unified Method for Data Mining (ASUM-DM). Die beiden iterativen Prozessmodelle lassen sich ferner gut mit agilen Entwicklungsmethoden – wie Scrum – kombinieren. So können die Use Cases sukzessive verfeinert und ergänzt werden. Das Beispiel einer Fehlererkennung verdeutlicht dies.
Das beschriebene Use Case zielt auf die frühzeitige Erkennung von bestimmten Fehlern respektive Fehlertypen ab. Für die Ausführung mit ML folgt daraus, dass alle spezifischen Fehler, die detektiert werden sollen, in ausreichender Menge in den Trainingsdaten vorhanden und genau beschriftet sein müssen. Das bedingt, dass die Fehler in der Vergangenheit bereits aufgetreten und von Experten erkannt/beschriftet worden sind.
Zu Beginn des Projekts liegen solche Daten in der Regel nicht vor, auch weil derartige Fehler im realen Betrieb der Anlage so gut wie nie vorkommen. Daher bietet es sich an, am Anfang etwas einfacher zu starten und zunächst ein Modell des normalen Verhaltens zu lernen.
Zu diesem Zweck werden lediglich die Daten aus dem regulären Betrieb – also ohne Fehler – benötigt. Das Modell wird dann trainiert, um Abweichungen vom Normalverhalten festzustellen. Auf diese Weise werden zwar keine bestimmten Fehler erkannt, aber ein erster Mehrwert erzielt.
Die detektierten Anomalien lassen sich anschließend von Experten bewerten sowie als spezifische Fehler identifizieren und beschriften. Im Laufe der Zeit entsteht so eine Datenbasis für ein Modell, das die eingetretenen Fehler erkennt und eventuell auch vorhersagen kann. Im Zuge dieser Verfeinerung durch Experten können die Anforderungen an die Datenqualität, die Notwendigkeit zusätzlicher Sensoren oder andere Informationen erfasst und umgesetzt werden.
Direkte Ankopplung an die Proficloud
Mit dem offenen Ecosystem PLCnext Technology werden Steuerungen von Phoenix Contact zu echten Edge Devices. Ein wesentlicher Grund für die Integration einer Vorverarbeitung in lokale Anwendungen respektive Steuerungen oder Edge Devices ist die Optimierung direkt vor Ort, die nicht von externen Daten oder Big Data abhängig sein muss.
An dieser Stelle erweist es sich als wichtig, Latenzen zu verringern und den Datenverkehr über mehrere Systemgrenzen zu vermeiden. Die Daten für Machine-Learning-Entscheidungen kommen direkt von der Steuerung und belasten die Infrastruktur der Anlage nicht. Somit lassen sich dedizierte Verbindungen einsparen. Darüber hinaus kann auf eine Verbindung in die Cloud verzichtet werden, die zudem nicht immer möglich ist.
Besteht allerdings die Anforderung, die Ergebnisse der ML-Berechnung ebenfalls an ein überlagertes Cloud-System zu versenden, ist dies mit der PLCnext Technology selbstverständlich umsetzbar. Die direkte Ankopplung an die Proficloud von Phoenix Contact sorgt für eine einfache Parametrierung der sicheren Verbindung zur Cloud.