
.jpg)

Schritt für Schritt wird den Komponentenherstellern und Gerätebetreibern klar, dass Digitalisierung nicht nur mit dem Internet, sondern in erster Linie mit Daten zu tun hat. Liegen geeignete Daten vor, lassen sich Data-Science-Methoden, wie Algorithmen der Künstlichen Intelligenz (KI) einsetzen. Mit solchen Methoden sind nicht nur selbstfahrende Autos möglich, sondern auch intelligente Maschinen und Komponenten, die Wartungstermine vorhersagen, den Energiebedarf optimieren und Anomalien erkennen.
KI-Anwender besitzen oft keine relevanten Daten
Ein großes Problem in der Praxis ist, dass die meisten potenziellen KI-Anwender in der Maschinenbauwelt praktisch überhaupt keine geeigneten Daten besitzen. Insofern muss in einem ersten Schritt zunächst einmal für brauchbare Daten gesorgt werden. Technisch lässt sich dieses Vorhaben durch Abgreifen der vorhandenen Daten aus der Steuerung umsetzen. Das kommt allerdings nur für Baugruppen- und Maschinenhersteller in Frage, da Eingriffe in die Steuerung erforderlich sind. Ohne Eingriffe in die Steuerung lässt es sich durch nachträgliches Hinzufügen geeigneter Sensoren per Maschinen- beziehungsweise Anlagen-Retrofit und Nutzung der Sensordaten bewerkstelligen. Die dabei erhaltenen Daten werden von einem geeigneten Gateway aufbereitet und über einen sicheren Verbindungsweg in einem IT-System, zum Beispiel einer Datenbank, gespeichert. Dort stehen die Maschinendaten für nachfolgende Datenanalysen zur Verfügung. Zuvor ist in der Regel allerdings noch ein umfangreiches Preprocessing erforderlich, da Sensorrohdaten Ausreißer und andere Störgrößen enthalten, die die Ergebnisse verzerren können.
Datenanalysen mit KI-Algorithmen und Data-Science-Methoden, wie beispielsweise das in der Finanzwelt weit verbreitete Time Series Forecasting (TSF) ermöglichen Predictive Analytics im Umfeld von Maschinen und Anlagen. Dadurch bestehen folgende Optimierungsmöglichkeiten:
Predictive Maintenance: Durch Datengewinnung mittels geeigneter Algorithmen lassen sich ungeplante Maschinenstillstände vermeiden. Mit Hilfe moderner Data-Science-Methoden sind inzwischen zum Beispiel auf Tage genaue Aussagen zur Ausfallwahrscheinlichkeit von Antrieben in Maschinen möglich. Damit lassen sich die erforderlichen Ersatzteile unter Berücksichtigung der Lieferzeiten frühzeitig bestellen und zu einem geeigneten Zeitpunkt einbauen.
Predictive Quality: In jeder Maschine gibt es Werkzeuge, deren aktueller Zustand maßgeblich Einfluss auf die Qualität des Endprodukts hat. In Anlagen sieht es bezüglich wichtiger Hilfsstoffe ähnlich aus. Ein Daten-Retrofit über zusätzliche Sensoren mit nachfolgender Datenanalyse ermöglicht Vorhersagen zur Qualität der finalen Produkte. Mit Predictive Analytics kann beispielsweise der Zeitpunkt vorhergesagt werden, ab wann eine Maschine zukünftig Ausschuss produziert. Durch rechtzeitige Eingriffe, etwa einen Werkzeugtausch, lässt sich so etwas verhindern.
Predictive Efficiency: Ein Verbund aus vielen Maschinen in einer Fabrik erzeugt hin und wieder Strombezugsspitzen, die zu hohen Stromkosten führen können. Intelligente Algorithmen, die über eine Retrofit-Sensorik mit Daten versorgt werden und darüber hinaus mittels Aktoren die Leistungsaufnahme einiger Maschinen drosseln können, helfen dabei, Energie effizienter zu nutzen. Im einfachsten Fall – also ohne die Aktoren – lassen sich durch Datenanalysen auch Maschinen- und Anlagenfahrpläne erstellen, die manuell umgesetzt werden und deren Sequenz zur Kosteneinsparung beiträgt.
Predictive Service mit Hilfe einer automatisierten Anomalieerkennung: Die Status- und Fehlermeldungen eines bestimmten Maschinentyps werden in der Cloud oder auf einem zentralen Server gespeichert. Mit einem an die Daten angepassten Preprocessing und der dann folgenden Analyse erfolgt die Auswertung und Informationsgewinnung.
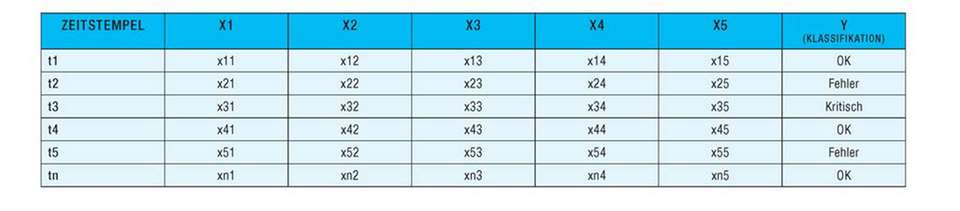
An der Schnittstelle zwischen Datenerfassung und -analyse werden die erhobenen Informationen in einem Format benötigt, das die existierenden Data-Science-Werkzeuge unterstützen. Nebenstehende Tabelle zeigt ein generisches Beispiel dafür: In den Spalten X1 bis X5 der Tabelle wurden verschiedene Datenpunkte einer Steuerung und die Rohdaten einzelner Sensoren in einem Datensatz zusammengefasst und mit einem Zeitstempel versehen. Aus dem Zeitstempel geht hervor, wann die Daten eines Datensatzes gemessen wurden. In der Praxis können nun beliebig viele gleichartige Datensätze in einer Datei zusammengefasst und analysiert werden. Nahezu alle Datenanalysewerkzeuge akzeptieren das altbekannte CSV-Dateiformat als Input.
Mittels einer deskriptiven Datenanalyse, also einer manuellen statistischen Analysemethode, lassen sich etwa die Lagemaße der Spalten X1 bis X5 und die zentrale Tendenz der Häufigkeitsverteilung ermitteln und graphisch darstellen. Als Lagemaße können das Minimum, Maximum, arithmetisches Mittel, der Modus, Median sowie das untere und obere Quantil bestimmt werden. Auch statistische Streuungsmaße, also die Variabilität der Häufigkeitsverteilung, zum Beispiel Spannweite, Standardabweichung, Interquartilsabstand, sind per Datenanalysewerkzeug für sehr große CSV-Dateien mit einer Struktur gemäß der unten stehenden Tabelle recht schnell berechenbar.
Maschinen die Datenanalyse beibringen
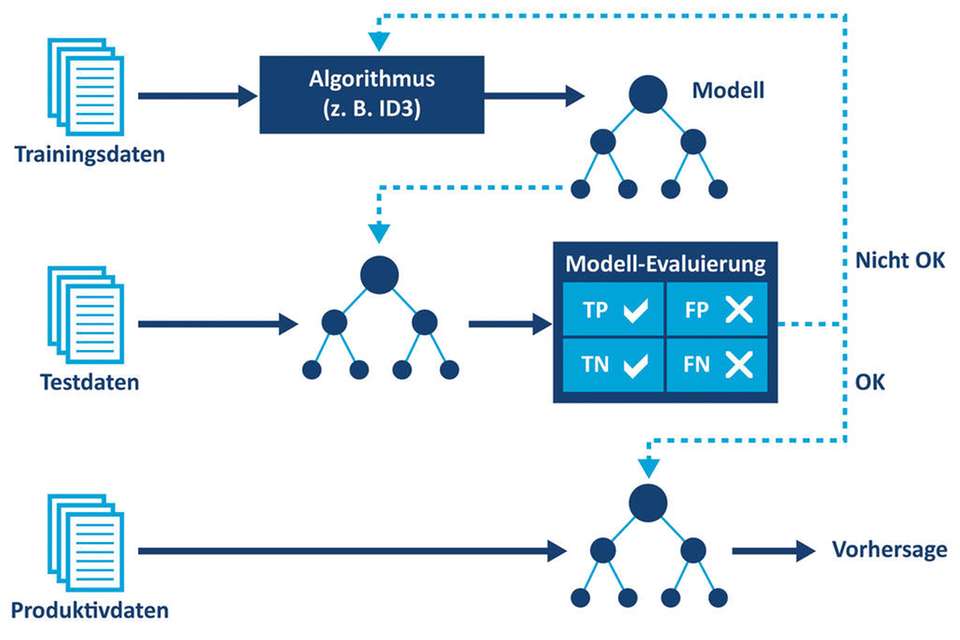
KI-Algorithmen, wie das sehr populäre und weit verbreitete Machine Learning, erfordern für die Datenanalyse eine Trainingsphase, bevor per Klassifikation, Mustererkennung und Vorhersage verwertbare Ergebnisse zu erwarten sind. Stehen nur relativ wenige Daten zur Verfügung, lässt sich dafür das überwachte Lernen (Supervised Machine Learning) nutzen. Dazu sind allerdings entsprechend vorbereitete Trainingsdaten notwendig, in denen jeder einzelne Datensatz einer bestimmten Klasse zugeordnet ist. In untenstehender Tabelle ist die Y-Spalte für die Klassifikation eines Datensatzes vorgesehen. In dieser kann beispielsweise ein Maschinen- oder Anlagenzustand wie „OK“, „Fehler“ oder „Kritisch“ gekennzeichnet werden.
In der Praxis müssen Trainingsdaten für das Supervised Machine Learning erst einmal erzeugt werden. Die dafür erforderliche Vorgehensweise und Zeitspanne muss für jeden Anwendungsfall individuell bestimmt werden. Insgesamt ergibt sich ein beschleunigter Learning-Effekt, wenn man für jeden X-Messwert mit Hilfe einer deskriptiven Datenanalyse die normalen und unnormalen Bereiche bestimmt. Datensätze mit einzelnen Ausreißern, also mindestens einem Messwert im unnormalen Bereich, werden mit entsprechendem Expertenwissen genauer untersucht und klassifiziert. Eine andere Möglichkeit ist, zum Beispiel im Rahmen eines größeren Feldtests, die anfallenden Daten zunächst einmal durch unüberwachtes Lernen (Unsupervised Machine Learning) mit Hilfe einer Clusteranalyse in Ähnlichkeitsgruppen unterteilen zu lassen. Die dabei entstehenden Gruppen und Gruppenzuordnungen der einzelnen Datensätze schaut sich ein Experte von Zeit zu Zeit an, um daraus Trainingsdaten für das überwachte Lernen abzuleiten.









.jpg "Investitionen in moderne Energiesysteme sichern Deutschlands Zukunft")
