


Für Benutzer von Cloud-Servern ist die traditionelle Serverarchitektur eine Herausforderung. Multicore-Prozessoren sind hocheffektiv, wenn es um die Ausführung von Software geht, die Entscheidungen auf Basis kleiner Datenmengen treffen soll. Bei Big-Data-Anwendungen werden jedoch ihre Grenzen sichtbar. Ein Hauptproblem von Systemen, die auf Mikroprozessoren beruhen, ist die relativ ineffiziente Nutzung des Arbeitsspeichers. Datenelemente müssen aus dem Arbeitsspeicher abgerufen, in temporären Registern zwischengespeichert und nach Abschluss der Operation zurück in den Arbeitsspeicher geladen werden – selbst dann, wenn dieselben Daten in verschiedenen Zyklen benötigt werden.
Um die Nachteile einer ununterbrochenen Übertragung von Daten zwischen Registern und Arbeitsspeicher zu beseitigen, erfanden Prozessor-Architekten den Cache-Speicher. Die Strategien der Cache-Verwaltung passen allerdings nicht immer zu den Mustern der Softwarenutzung. Adresskonflikte können dazu führen, dass wichtige Daten von einem anderen Element, das die Cachezeile benötigt, in den Arbeitsspeicher geladen werden, kurz bevor jenes erste Datenelement erforderlich wird.
Grafikprozessoren schaffen Abhilfe
Spezielle Prozessoren, die für die Signal- oder Bildverarbeitung optimiert wurden, nutzen per Software verwaltete On-Chip-Zwischenspeicher, um Daten effizienter zu übertragen. Bei solchen Implementierungen besteht jedoch weiterhin der Nachteil, dass eine befehlsorientierte Architektur auf Probleme angewandt wird, bei denen es um große Datenströme geht. Betreiber von Serverfarmen nutzen aber inzwischen erfolgreich Grafikprozessoren (GPUs) für Big-Data-Anwendungen. Dabei profitieren sie von der massiven Parallelverarbeitung, die derartige Prozessorarchitekturen möglich machen.
Ein Problem ist, dass GPUs zur Bereitstellung hoher Rechenleistung eine Menge Energie benötigen. Eine andere Möglichkeit, um in Datenstromanwendungen auf massive Parallelverarbeitung zurückzugreifen, ist das Field-Programmable Gate Array (FPGA). In Bereichen wie der Luftfahrtelektronik, Kommunikationsinfrastruktur und Bildverarbeitung gehören FPGAs seit langem zum Standard.
Viele dieser Anwendungen weisen hinsichtlich der Architektur große Ähnlichkeiten mit der Big-Data-Verarbeitung auf, die Cloud-Benutzer heute in Anspruch nehmen möchten. Die von großen Internetfirmen entwickelten maßgeschneiderten Beschleuniger basieren zum Beispiel auf Architekturen wie systolischen Arrays, um die Performance von AI-Anwendungen zu verbessern, die auf Convolutional Neural Networks beruhen. Systolische Arrays kommen beispielsweise beim Militär im Rahmen der Verarbeitung von Radardaten zum Einsatz.
FPGAs als Lösung für Big-Data-Anwendungen
Es gibt viele Gründe, warum FPGAs (Field Programmable Gate Array) eine sinnvolle Lösung für cloudbasierte Big-
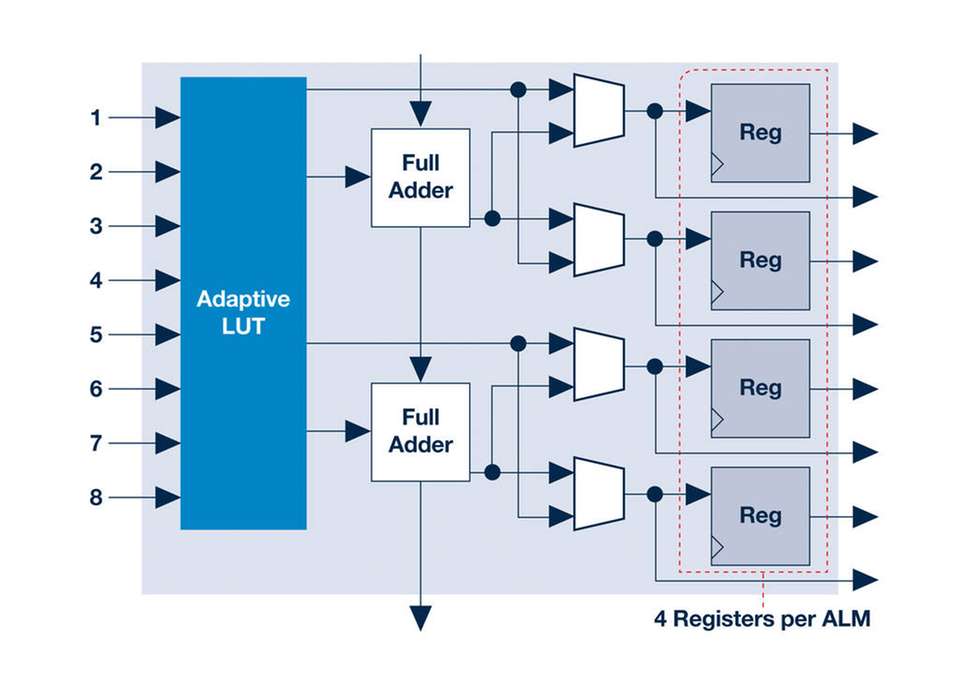
Data-Anwendungen sind. Der zentrale Logik-Block, der in FPGAs viele Male repliziert wird, besteht aus einer programmierbaren Wertetabelle. Jede Funktion, die sich als Wahrheitstabelle ausdrücken lässt und in die Tabelle passt, kann implementiert werden. Meist speisen einzelne Lookup-Tabellen ein oder mehrere Register. Zusätzliche Schaltungen wie Carry-Chain-Eingänge und -Ausgänge ermöglichen eine effiziente Implementierung arithmetischer Einheiten.
Die Logik-Blöcke werden mithilfe programmierbarer Switches in einem chipweiten Verbindungs-Fabric miteinander verdrahtet, um komplexe kombinatorische Logik-Schaltungen zu bilden. Wichtig dabei ist, dass sich Verbindungen spontan umprogrammieren lassen, indem eine neue Konfigurationsdatei aus dem Arbeitsspeicher geladen wird. So kann das FPGA mit demselben Silizium verschiedene Anwendungen
unterstützen.
Gesamtperformance erhöhen
FPGAs, wie sie zum Beispiel von Intels Programmable Systems Group angeboten werden, umfassen zahlreiche andere Leistungsmerkmale, welche die Gesamtperformance erhöhen. Dazu gehören unter anderem arithmetische Logik-Einheiten, die für die Ausführung von DSP-Funktionen (Digitalsignalverarbeitung) optimiert wurden, beispielsweise Multiplay-Adds. Durch zwei unterschiedliche DSP-Implementierungen eignen sich FPGAs perfekt für die Verarbeitung der Datenfeeds aus Sensoren sowie der Algorithmen für maschinelles Lernen, die von tiefen neuronalen Netzwerken benötigt werden. Große Speicherblöcke ermöglichen eine Pufferung und
Zwischenspeicherung.
Entscheidend für die Beschleunigung von Big-Data-Anwendungen durch FPGAs ist das Zusammenfassen dieser Blöcke in individuellen Pipelines. Anstatt Daten zwischen Prozessor und Arbeitsspeicher hin und her zu übertragen, können Lookup-Tabellen Daten dahin leiten, wo sie der nächste Knoten benötigt.
Das passt zum Modell der Daten-Pipelines, das viele Big-Data-Anwendungen aufweisen. Ein weiterer Vorteil von FPGAs besteht darin, dass sich der Lookup-Vorgang mit einer Synthetisierung benutzerdefinierter Verarbeitungselemente kombinieren lässt. Dazu können kleine Mikroprozessoren beitragen, die Daten durch die fest verdrahteten Prozessoren sequenzieren. Alternativ können sie Teil der Datenpipeline sein – mit einem Schwerpunkt auf benutzerdefinierten Datentypen, die auch spezialisierte 2-Bit-Nibbles umfassen können, welche die Basenpaare einer genetischen Sequenz repräsentieren.
Lernende Netzwerke
Anpassungsfähige Ausführungseinheiten sind für AI-Algorithmen genauso wichtig, vor allem in der Inferenzphase. Standardmäßige Gleitkomma-Operationen mit einfacher Präzision stellen beim Trainieren einen guten Ausgangspunkt für die Berechnung von Neuronengewichtungen dar. Nach dem Training des Netzwerks wird hohe Genauigkeit jedoch nur noch für eine Untergruppe der Neuronengewichtungen
benötigt.
Viele Gewichtungen mit einer geringeren Auswirkung auf die Gesamtleistung lassen sich mit einer deutlich niedrigeren Präzision bearbeiten. Das kann bis hin zu 4-Bit- oder 8-Bit-Festkomma-Datentypen reichen. Da
FPGAs eine Anpassung der Verarbeitung an spezifische Algorithmen ermöglichen, steigt die Energieeffizienz. Standardmäßige Multicore-Prozessoren und GPUs können da nicht mithalten. Die Rechenbeschleunigung ist nicht der einzige Punkt, an dem FPGAs als zentrale Komponente von Rechenzentrumsarchitekturen immer wichtiger werden. Anwendungen, die in Rechenzentren ausgeführt werden, setzen vermehrt auf Virtualisierung und Container-Frameworks wie Docker, um Workloads bei Bedarf leichter handhaben zu können.
Eine Folge davon ist, dass verbundene Anwendungen mithilfe standardmäßiger TCP/IP-Protokolle kommunizieren, Pakete jedoch nicht in das übergeordnete Netzwerk übertragen werden. Dieser kleine Grenzverkehr kann auf den Servern, die den von ihnen gehosteten virtuellen Maschinen vollständige Netzwerk-Stacks und -Services bereitstellen müssen, einen hohen Overhead verursachen.
Den Datenverkehr richtig steuern
In herkömmlichen Netzwerkdesigns übernehmen Application-Specific Integrated Circuits (ASICs) und dedizierte Netzwerkprozessoren die Weiterleitung von Paketen und die Verwaltung des Datenverkehrs. Auf dem Server sorgt Software wie beispielsweise OpenDataPlane oder DPDK für die Bereitstellung der erforderlichen virtualisierten Services. Da für die Verarbeitung von Big Data jedoch Geschwindigkeiten von mehreren Gigabit pro Sekunde benötigt werden, kann die Software in einer Multicore-CPU mehrere Prozessoren in Anspruch nehmen.
Lösung: Smart-NIC
Mit einer Smart-NIC lässt sich dieses Problem leicht lösen. Sie stellt eine Linux-basierte Engine für die Paketverarbeitung bereit, die für Standardsoftware eine Multicore-CPU einsetzt, aber auch Beschleuniger und Paketweiterleitungs-Engines nutzen kann, die in benutzerdefinierter Logik implementiert sind. Eine Möglichkeit besteht darin, die gleichen ASICs zu verwenden, die auch in Switches der Telekommunikationsbranche zum Einsatz kommen. Diesen fehlt es jedoch an Flexibilität, die zur Unterstützung unterschiedlicher Anwendungen auf Servern im Rechenzentrum benötigt wird. Für Kommunikation optimierte FPGAs wie MachXO3 von Lattice Semiconductor und Igloo2 von Microsemi, die über schnelle
SerDes-Links kommunizieren können, stellen diesbezüglich eine bessere Plattform dar.
Ausblick
Der Umstieg auf flexible Hardware in Smart-NIC-Plattformen wird durch die Einführung neuer Programmiersprachen und Konvertierungstools für C-Software erleichtert, die Paketweiterleitungslogik in Hardwareschaltungen umsetzen können. Eine Option ist die P4-Sprache, die speziell für Netzwerkaufgaben entwickelt wurde. Außerdem kann LLVM-Compiler-Technologie zur Umwandlung von C-Programmen dienen, damit sich diese in das FPGA-Fabric herunterladen und als Kerne bereitstellen lassen. Abschließend sehen wir uns das Problem der Leistungs- und Systemsteuerung an. Die Server-Blades selbst haben komplexe Leistungsanforderungen. In solchen Umgebungen können FPGAs wie SmartFusion und
Igloo2 von Microsemi für die erforderliche echtzeitbasierte Leistungssteuerung sorgen. Betrachtet man die zuvor beschriebenen Trends, haben FPGAs in der Cloud sicherlich eine große Zukunft vor sich.

.jpg)
SIGMATEK.jpg "Multitouch-HMIs für umfangreiche Visualisierungen")

%20(1).jpg "Videointerviews von der Embedded World 2026")





