Kryptografie-Bibliotheken oder GUI-Toolkits werden heute in aller Regel von Dritten bezogen, entweder als Open-Source-Projekte oder als meist binäre, kommerzielle Produkte. Auch im Embedded-Bereich nimmt der Anteil an Code-Komponenten aus externen Quellen beständig zu, Marktbeobachter wie VDC Research schätzen diese Quote auf aktuell 30 Prozent.
Dagegen ist nichts einzuwenden. Denn die Nutzung dieser Komponenten erlaubt es den Entwicklern, sich auf die eigentliche Funktionalität zu konzentrieren. Aus Sicht der Qualitätssicherung hingegen ist der Einsatz von Bibliotheken jedoch kritisch. Denn diese lassen sich nicht ohne Weiteres auf Fehlerfreiheit – oder gar böswilligen Code – untersuchen. Die Validierung und die Verifikation eines entsprechenden Systems werden also deutlich erschwert.
Ein grundsätzliches Problem dabei ist, dass der Code von Zulieferern oft nur binär vorliegt. Dieser lässt sich mit den üblichen Mitteln der statischen Analyse nur schwer überprüfen: Die statische Code-Analyse erstellt normalerweise aus dem Quellcode eine Intermediate Representation (IR), die dann analysiert wird.
Binärcode allerdings ist nicht strukturiert, die für eine IR notwendigen Informationen fehlen. Eine Ausnahme bildet hier zum Beispiel CodeSonar von Grammatech. Das Tool ist in der Lage, auch aus binärem Code durch Deassemblieren ein analysierbares Modell zu erstellen und den dabei entstehenden Assembler-Code für die Entwickler in C zu übertragen.
Fehlende Spezifikationen
Das zweite, schwerwiegendere Problem stellen die APIs dar. Die Application Programming Interfaces dienen dazu, den fremden Code aus dem eigenen Programm heraus anzusprechen und einzelne Funktionen gezielt zu nutzen. Anders als bei einer Binärschnittstelle erfolgt in einer Programmierschnittstelle die Anbindung rein auf der Quelltext-Ebene. Die Übergabe der Daten und Befehle erfolgt strukturiert nach einer definierten Syntax. Weist diese jedoch Dokumentationsfehler oder Lücken auf, kann es zu ungewollten Zuständen kommen.
Eine exakte Festlegung der Eingabe- und Ausgabeparameter ist also zwingend. Auch ist der Einsatz nicht formal spezifiziert. Standards, die die Nutzung von APIs verbindlich regeln, gibt es nicht. Gleichzeitig weisen die meisten APIs eine immense Vielfalt an Funktionen auf, ihr Einsatz ist alles andere als trivial.
Damit gibt es zahlreiche Möglichkeiten, Fehler zu machen, die nur schwer aufzuspüren sind. Sie führen oft zu Performance-Problemen oder zu Schwierigkeiten mit der Stabilität des Systems. Im schlimmsten Fall entstehen durch diese Fehler schwerwiegende Sicherheitslücken.
Die üblichen Methoden der Evaluierung und Validierung von Software tun sich schwer, potenzielle Fehler bei der API-Nutzung zu erkennen. Das dynamische Testing erkennt grundsätzliche Fehler nur, wenn der Testfall den fehlerhaften Code durchläuft, der Fehler dabei zu einer Error Condition und schließlich diese Error Condition für eine Abweichung vom erwarteten Ergebnis führt.
Die entsprechende statische Code-Analyse hingegen, die den Code in eine IR überführt und anhand dieser alle Daten- und Steuerungsströme analysiert, basiert auf Checkern, die das Vorhandensein bestimmter Muster überprüfen. Durch die fehlende formale Spezifikation der API-Nutzung müsste für jede API ein eigener Checker-Satz definiert werden. Das ist wirtschaftlich und praktisch nicht zu leisten.
Neue Regeln durch Lernen
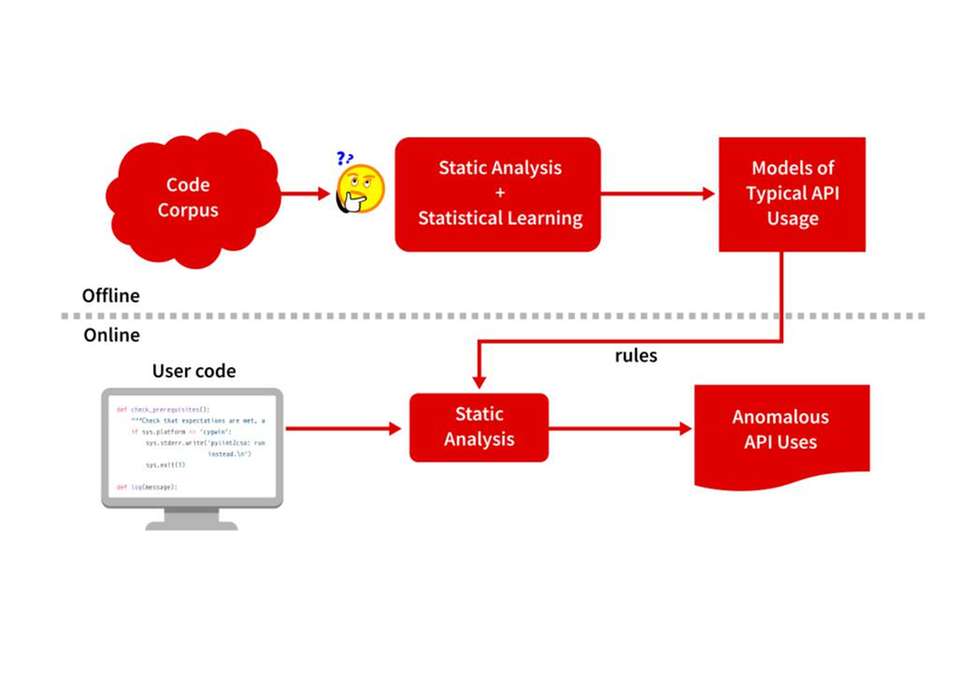
Durch die rasanten Fortschritte bei Künstlicher Intelligenz und maschinellem Lernen eröffnet sich jedoch ein neuer Ansatz: Geht man davon aus, dass die meisten API-Einsätze korrekt sind, können durch maschinelles Lernen aus einer hinreichend großen Code-Sammlung entsprechende Regeln für spezifische APIs abgeleitet werden.
Entscheidend ist dabei, dass zum einen die Qualität der Daten hinreichend gut ist. Zum anderen muss das Korpus so umfangreich sein, dass sich mit statistischen Methoden entsprechende Muster extrahieren lassen. Diesen Ansatz hat Grammatech jüngst in einem Projekt angewandt.
Dabei wurde der Quellcode von 7.000 in C oder C++ geschriebenen Open-Source-Projekten durch maschinelles Lernen ausgewertet. So konnten fast 500 Millionen Codezeilen untersucht werden. Das Hauptaugenmerk der Analyse lag auf dem Einsatz besonders häufig genutzter Bibliotheken wie GTK, Qt, OpenSSL, GLib, Gnu C Library oder XLib. Anhand der so erzeugten Daten konnte ein Modell erstellt werden, das den richtigen Einsatz der spezifischen API im eigenen Code definiert und so auf ein konkretes Projekt angewandt werden kann.
Beispiele für unnötige Sicherheitslücken
Ein recht häufig auftretendes Problem, das durch diesen Ansatz aufgespürt werden kann: Das Ergebnis einer Funktion wird im weiteren Verlauf nicht genutzt, in der Folge bleibt eine unnötige Sicherheitslücke offen. So etwa in folgendem Beispiel:
Die Funktion g_strescape () aus der GLib-Bibliothek dient dazu, Escape-Sequenzen zu maskieren. Hier fungiert sie als Sanitizer des Input-Strings param_str, es wird ein neuer String zurückgegeben.
Dieser Wert wird allerdings im weiteren Verlauf nicht genutzt. Stattdessen wird mit dem unbereinigten String param_str eine SQL-Query erzeugt – ein mögliches Einfallstor für SQL-Injections. Hier hatte der Entwickler womöglich angenommen, dass g_strescape den Input-String modifiziert. Der Fehler wurde vom Analyse-Tool CodeSonar erkannt, der Entwickler bekommt zahlreiche Details zur einfachen Beseitigung angezeigt.
Ähnlich war der Fehler in einem anderen Projekt gelagert: Hier wurde die Funktion g_list_sort () aus der GLib-Bibliothek nicht korrekt genutzt. Die Funktion sortiert eine verkettete Liste anhand der als Parameter übergebenen Vergleichsfunktion. Dadurch kann sich der Listen-Header ändern. Die Funktion gibt den neuen Listen-Header aus. Auch in diesem Beispiel erstellt CodeSonar die Warnung, dass das Ergebnis g_lib_sort im weiteren Ablauf des Programms nicht genutzt wird.
Durch die an die API-Funktion übergebenen Parameter compare_func kann es allerdings sein, dass sich der Listen-Header durch die Sortierung geändert hat. Damit ist es möglich, dass dir_list nun auf ein arbiträres Element der Liste verweist und nicht mehr zwingend auf den Listenanfang. Im weiteren Verlauf führt das zu einem Speicherleck: Mit g_list_free wird nur ein Teil der Liste freigegeben, der nach dem bisherigen Header steht. Denn auf diesen verweist dir_list.
Der Entwickler umgeht dieses Problem durch die Funktion g_list_first – ein unnötiger Schritt, denn diese Informationen wurden bereits von g_lib_sort ermittelt. Der Code ist an dieser Stelle also nicht effizient. Der fehlerhafte Einsatz der Funktion g_list_sort findet in diesem Projekt durchgängig statt. Mit den herkömmlichen Analyseansätzen wäre dieses Problem kaum zu erkennen gewesen, denn durch die Konsistenz bei der Nutzung und die fehlende formale Spezifikation kann ein Analyse-Tool nicht auf einen Fehler schließen.
Fazit
Künstliche Intelligenz und maschinelles Lernen stehen im Bereich der Code-Analyse noch am Anfang. Doch bereits jetzt ermöglichen diese Technologien Analysen und Fehlererkennungen, die vor wenigen Jahren noch unerreichbar schienen.
Es ist zu erwarten, dass dadurch in den kommenden Monaten und Jahren massive Fortschritte gemacht werden, die letztlich die Code-Qualität erhöhen und damit die Sicherheit von Embedded-Systemen signifikant voranbringen. Bedenkt man, welche zentrale und wichtige Rolle Embedded-Devices bereits heute in vielen Geschäftsmodellen, in der Medizintechnik oder der Automobilbranche spielen, kann die Relevanz besserer Analyse-Werkzeuge kaum überbewertet werden.