




KI-Anwendungen haben einen enormen Energieverbrauch durch Serverfarmen oder teure FPGAs. Die Herausforderung besteht dabei darin, die Rechenleistung zu erhöhen und gleichzeitig den Energieverbrauch und die Kosten niedrig zu halten. Derzeit erleben KI-Anwendungen einen dramatischen Wandel, der durch leistungsstarkes Intelligent-Edge-Computing ermöglicht wird. Im Vergleich zu herkömmlichen Firmware basierten Berechnungen läutet die hardwarebasierte Beschleunigung neuronaler Faltungsnetze mit ihrer beeindruckenden Geschwindigkeit und Leistung eine neue Ära der Rechenleistung ein.
Indem sie Sensorknoten in die Lage versetzt, ihre eigenen Entscheidungen zu treffen, reduziert die Intelligent-Edge-Technologie die Datenübertragungsraten über 5G- und WIFI-Netzwerke drastisch. Dies ermöglicht neue Technologien und einzigartige Anwendungen, die zuvor nicht möglich waren. So werden beispielsweise Rauch-/Brandmelder an abgelegenen Orten oder die Analyse von Umweltdaten direkt auf Sensorebene möglich – und das alles bei jahrelangem Betrieb mit einer Batterie. Um zu untersuchen, wie diese Funktionen möglich werden, befasst sich dieser Artikel mit der Hardwareumsetzung eines CNN mit einem speziellen KI-Mikrocontroller.
Mikrocontroller für KI mit Ultra-Low-Power-Beschleuniger für neuronale Faltungsnetzwerke
Der MAX78000 ist ein KI-Mikrocontroller mit einem Ultra-Low-Power-CNN-Beschleuniger, einem fortschrittlichen System-on-Chip. Es ermöglicht neuronale Netzwerke bei extrem niedrigem Stromverbrauch für ressourcenbeschränkte Edge-Geräte oder IoT-Anwendungen. Zu diesen Anwendungen gehören Objekterkennung und -klassifizierung, Audioverarbeitung, Geräuschklassifizierung, Rauschunterdrückung, Gesichtserkennung, Verarbeitung von Zeitreihendaten für die Analyse von Herzfrequenzen und sonstigen medizinischen Signalen, Multisensoranalyse und vorbeugende Wartung.
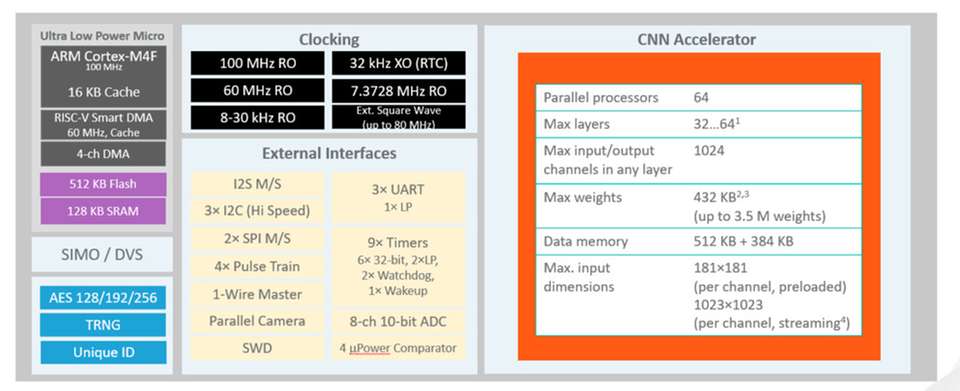
Abbildung 1 zeigt ein Blockschaltbild des MAX78000, der von einem ARM Cortex-M4F-Kern mit Fließkomma-Einheit mit bis zu 100 MHz gesteuert wird. Um Anwendungen ausreichend Speicherressourcen zur Verfügung zu stellen, verfügt diese Version der MCU über 512 kB Flash-Speicher und 128 kB SRAM. Es sind mehrere externe Schnittstellen wie I²Cs, SPIs, UARTs sowie die für Audioanwendungen wichtige I²S-Schnittstelle vorhanden. Zusätzlich ist ein 60-MHz-RISC-V-Kern integriert. Der RISC-V-Kern kopiert Daten von/zu den einzelnen Peripherieblöcken und dem Speicher (Flash und SRAM), was ihn zu einer intelligenten Direct Memory Access (DMA)-Engine macht. Der RISC-V-Kern verarbeitet die Sensordaten für den KI-Beschleuniger vor, so dass sich der ARM-Kern während dieser Zeit im Tiefschlafmodus befinden kann. Bei Bedarf kann das Ergebnis der Inferenz den ARM-Kern über einen Interrupt aktivieren, woraufhin die ARM-CPU Aktionen in der Hauptanwendung ausführt, Sensordaten drahtlos weiterleitet oder den Benutzer informiert.
Ein Hardware-Beschleuniger für die Durchführung von Inferenzen in neuronalen Faltungsnetzen ist ein besonderes Merkmal der MCUs der MAX7800x-Serie, das sie von der Standard-MCU-Architektur und -Peripherie unterscheidet. Dieser Hardware-Beschleuniger unterstützt komplette CNN-Modelle zusammen mit allen erforderlichen Parametern (Gewichte und Vorspannungen). Der CNN-Beschleuniger ist mit 64 parallelen Prozessoren und einem integrierten Speicher mit 442 kB für die Speicherung der Parameter und 896 kB für die Eingangsdaten ausgestattet. Da das Modell und die Parameter im SRAM-Speicher abgelegt sind, können diese über die Firmware geändert, und das Netz somit in Echtzeit angepasst werden. Je nachdem, ob im Modell 1-, 2-, 4- oder 8-Bit-Gewichte verwendet werden, kann dieser Speicher für bis zu 3,5 Millionen Parameter ausreichen. Da der Speicher ein integraler Bestandteil des Beschleunigers ist, müssen die Parameter nicht bei jeder aufeinanderfolgenden mathematischen Operation über die MCU-Busstruktur abgerufen werden. Dieser Vorgang ist aufgrund der hohen Latenzzeiten und des hohen Stromverbrauchs sehr kostspielig. Der Beschleuniger für neuronale Netze kann je nach der Pooling-Funktion 32 oder 64 Layer unterstützen. Die programmierbare Bildeingabe-/Ausgabegröße beträgt bis zu 1024x1024 Pixel für jeden Layer.
CNN Hardware-Konvertierung: Vergleich von Energieverbrauch und Inferenzgeschwindigkeit
Die Berechnung der CNN-Inferenz ist eine komplexe Aufgabe, die große lineare Gleichungen in Matrixform umfasst. Mit der Leistung von ARM Cortex-M4F-MCUs ist die Berechnung der CNN-Inferenz in der Firmware eines Embedded System möglich; es gibt jedoch einige Nachteile zu beachten. Bei Firmware-basierten Inferenzen, die auf MCUs durchgeführt werden, werden viel Energie und Zeit verbraucht, da die für die Berechnung erforderlichen Befehle zusammen mit den zugehörigen Parameterdaten aus dem Speicher abgerufen werden müssen, bevor Zwischenergebnisse zurückgeschrieben werden können.
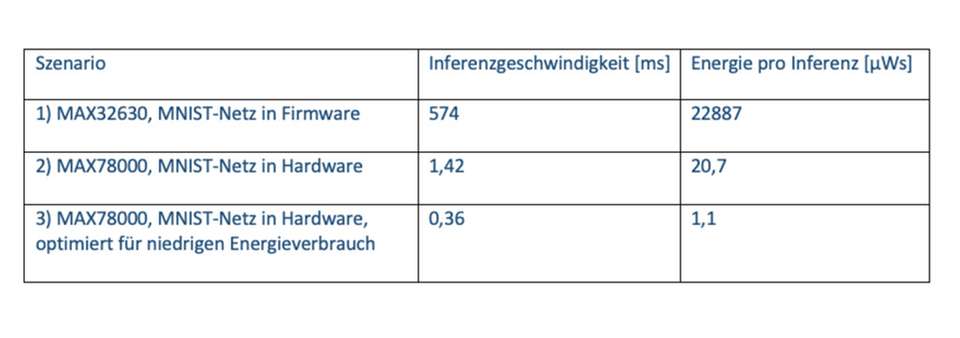
Tabelle 1 zeigt einen Vergleich der CNN-Inferenzgeschwindigkeit und des Energieverbrauchs unter Verwendung von drei verschiedenen Lösungen. Dieses beispielhafte Modell wurde unter Verwendung des MNIST-Datensatzes entwickelt und dient der Erkennung handgeschriebener Ziffern aus visuellen Eingangsdaten Die von den einzelnen Ansätzen benötigte Inferenzzeit und Energie wurde gemessen, um die Unterschiede darzustellen.
Im ersten Szenario wurde für die Berechnung der Inferenz ein in den MAX32630 integrierter ARM Cortex-M4F-Prozessor verwendet, der mit 96 MHz arbeitet. Im zweiten Szenario wurde zur Berechnung der hardwarebasierte CNN-Beschleuniger des MAX78000 verwendet. Die Inferenzgeschwindigkeit – das heißt die Zeit zwischen der Präsentation der visuellen Daten am Netzwerkeingang und der Ausgabe des Ergebnisses – ist bei Verwendung einer MCU mit einem hardwarebasierten Beschleuniger (MAX78000) um den Faktor 400 geringer. Zudem ist die benötigte Energie pro Inferenz um den Faktor 1100 niedriger. In einem dritten Vergleich wurde das MNIST-Netzwerk auf minimalen Energieverbrauch pro Inferenz optimiert. Die Genauigkeit des Ergebnisses sinkt in diesem Fall von 99,6 Prozent auf 95,6 Prozent. Allerdings ist das Netz in diesem Fall viel schneller und benötigt nur 0,36 ms pro Inferenz. Der Energieverbrauch sinkt auf nur 1,1 µWs pro Inferenz. Bei Anwendungen, die zwei AA-Alkalibatterien (insgesamt 6 Wh) verwenden, sind fünf Millionen Inferenzen möglich (der Stromverbrauch der restlichen Schaltung ist hierbei nicht berücksichtigt).
Diese Daten veranschaulichen die Leistungsfähigkeit hardwarebeschleunigter Berechnungen. Hardware-beschleunigtes Rechnen ist ein unschätzbares Werkzeug für Anwendungen, die nicht auf Konnektivität oder eine kontinuierliche Stromversorgung zurückgreifen können. Der MAX78000 ermöglicht Edge-Verarbeitung, ohne dass große Energiemengen oder ein Breitband-Internetzugang erforderlich sind.
Beispielhafter Anwendungsfall für den AI-Mikrocontroller MAX78000
Der MAX78000 ermöglicht eine Vielzahl von Anwendungen, wobei wir beispielhaft den folgenden Anwendungsfall untersuchen. Die Anforderung besteht darin, eine batteriebetriebene Kamera zu entwickeln, die erkennt, wenn sich eine Katze im Sichtfeld ihres Bildsensors befindet, und daraufhin über einen digitalen Ausgang den Zugang zum Haus durch die Katzenklappe ermöglicht.
Abbildung 2 zeigt ein Blockschaltbild für ein solches Design. In diesem Fall schaltet der RISC-V-Kern den Bildsensor in regelmäßigen Abständen ein, wobei die Bilddaten in das vom MAX78000 gesteuerte CNN geladen werden. Wenn die Wahrscheinlichkeit, dass eine Katze erkannt wird, über einem vorher festgelegten Schwellenwert liegt, wird die Katzenklappe aktiviert. Das System kehrt anschließend in den Standby-Modus zurück.
Entwicklungsumgebungen und Evaluierungskits
Der Prozess der Entwicklung einer KI-gestützten Anwendung lässt sich in die folgenden Phasen unterteilen:
Phase 1: AI: Definition, Training und Quantisierung des Netzes
Phase 2: ARM-Firmware Einbindung der in Phase 1 generierten Netze und Parameter in die C/C++-Anwendung sowie Erstellung und Test der Anwendungsfirmware
Der erste Teil des Entwicklungsprozesses umfasst die Modellierung, das Training und die Evaluierung der KI-Modelle. In dieser Phase kann der Entwickler auf Open-Source-Tools wie PyTorch und TensorFlow zurückgreifen. Das GitHub-Repository bietet umfassende Ressourcen, die den Nutzern helfen, ihren Weg beim Aufbau und Training von KI-Netzwerken mit der PyTorch-Entwicklungsumgebung zu planen und dabei die Hardware-Spezifikationen des MAX78000 zu berücksichtigen. Das Repository enthält einige einfache KI-Netzwerke und Anwendungen wie Gesichtserkennung (Face ID).
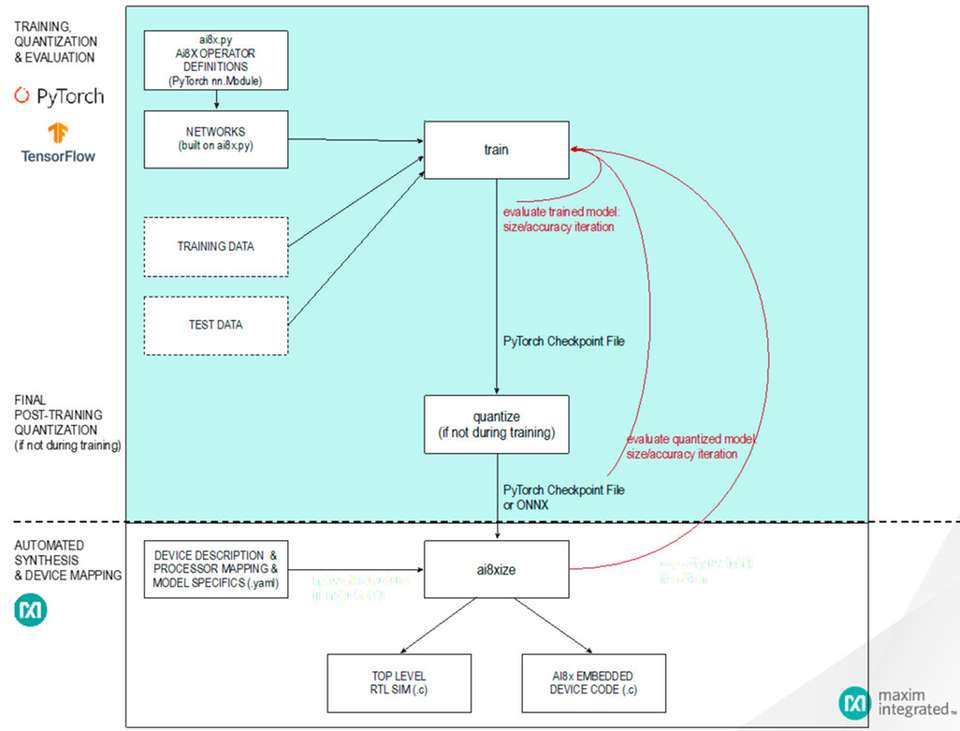
Abbildung 3 zeigt den typischen KI-Entwicklungsprozess in PyTorch. Zunächst wird das Netz modelliert. Es ist zu beachten, dass die MAX7800X MCUs nicht alle in der PyTorch-Umgebung verfügbaren Datenmanipulationen unterstützen. Aus diesem Grund muss zuerst die von Analog Devices mitgelieferte Datei „ai8x.py“ in das Projekt eingebunden werden. Diese Datei enthält die PyTorch-Module und Operatoren, die für die Verwendung des MAX78000 erforderlich sind. Auf Grundlage dieses Setups kann das Netz aufgebaut und anschließend anhand der Trainingsdaten trainiert, bewertet und quantisiert werden. Das Ergebnis dieses Schritts ist eine Checkpoint-Datei, die die Eingabedaten für den endgültigen Syntheseprozess enthält. In diesem letzten Prozessschritt werden das Netz und seine Parameter in eine Form umgewandelt, die auf den CNN-Hardwarebeschleuniger zugeschnitten ist. An dieser Stelle ist zu erwähnen, dass das Netzwerktraining mit jedem PC (Notebook, Server usw.) durchgeführt werden kann. Ohne die Unterstützung von CUDA-Grafikkarten kann dies jedoch selbst bei kleinen Netzwerken sehr viel Zeit in Anspruch nehmen, wobei Tage oder sogar Wochen durchaus realistisch sind.
In Phase 2 des Entwicklungsprozesses wird die Anwendungsfirmware mit dem Mechanismus zum Schreiben von Daten in den CNN-Beschleuniger und zum Lesen der Ergebnisse erstellt. Die in der ersten Phase erstellten Dateien werden über #include-Direktiven in das C/C++-Projekt integriert. Als Entwicklungsumgebung für die MCU werden zudem Open-Source-Tools wie Eclipse IDE und die GNU Toolchain verwendet. Analog Devices stellt ein Software Development Kit (Maxim Micros SDK (Windows)) als Installationsprogramm zur Verfügung, das bereits alle notwendigen Komponenten und Konfigurationen enthält. Das Software Development Kit enthält außerdem Peripherietreiber sowie Beispiele und Anleitungen, die die Entwicklung von Anwendungen erleichtern.
Sobald das Projekt fehlerfrei kompiliert und gelinkt wurde, kann es auf der Zielhardware evaluiert werden. ADI hat zu diesem Zweck zwei verschiedene Hardware-Plattformen entwickelt. Abbildung 4 zeigt das MAX78000EVKIT und Abbildung 5 zeigt das MAX78000FTHR, ein Board mit einem etwas kleineren Formfaktor. Jedes Board wird mit einer VGA-Kamera und einem Mikrofon geliefert.
Schlussfolgerung
Bisher hatten KI-Anwendungen einen enormen Energieverbrauch durch Serverfarmen oder teure FPGAs. Mit den MCUs der MAX78000-Familie – mit dediziertem CNN-Beschleuniger – ist es nun möglich, KI-Anwendungen über längere Zeiträume mit einer einzigen Batterie zu betreiben. Dieser Durchbruch hinsichtlich Energieeffizienz und Leistung macht Edge-AI zugänglicher als je zuvor und erschließt das Potenzial für neue und aufregende Anwendungen, die zuvor unmöglich waren. Weitere Informationen finden Sie unter: Ultra-Low Power Artificial Intelligence (AI) MCUs.
Teil 1 der Artikel-Serie: Was ist maschinelles Lernen
Teil 2 der Artikel-Serie: Das Training eines neuronalen Netzes








.jpg "Benchmark evaluiert Large Language Models automatisch")



