





Die Automatisierung der industriellen Produktionsprozesse entwickelt sich mit rasendem Tempo weiter. Alle beteiligten Komponenten wie Maschinen, Roboter, Transfer- und Handling-Systeme, Sensoren sowie Bildeinzugsgeräte sind durchgängig vernetzt, arbeiten nahtlos zusammen und kommunizieren über einheitliche Protokolle miteinander.
Zudem prägen immer mehr Roboter unterschiedlicher Bauart das Bild in den Montagehallen. Ein Trend in diesem Zusammenhang: Insbesondere kleine, kompakte und mobile Roboter übernehmen zahlreiche Aufgaben. Dabei kooperieren die sogenannten Collaborative Robots (Cobots) häufig eng mit ihren menschlichen Kollegen. Die Akteure reichen sich beispielsweise gegenseitig Bauteile und ergänzen sich perfekt im Rahmen von Montageprozessen.
Machine Vision als Auge der Produktion
Der zunehmend hohe Automatisierungsgrad erfordert unterstützende Technologien, welche die Wertschöpfungsprozesse begleiten. Eine Schlüsselrolle nimmt dabei die industrielle Bildverarbeitung (Machine Vision) ein. Die oft als „Auge der Produktion“ bezeichnete Technologie beobachtet und überwacht alle Fertigungsabläufe lückenlos. Über Bildeinzugsgeräte wie Kameras, Scanner und 3D-Sensoren werden große Mengen digitaler Bilddaten aus unterschiedlichen Perspektiven aufgenommen und gesammelt. Eine hochentwickelte Machine-Vision-Software verarbeitet diese Informationen und macht sie für weitere Glieder in der industriellen Prozesskette nutzbar. Damit ist es möglich, verschiedenste Objekte im Produktionsfluss ausschließlich aufgrund optischer Merkmale sicher zu identifizieren, deren Position exakt zu bestimmen und Produktionsfehler verlässlich zu erkennen.
Dieser Erkennung der Gegenstände geht ein Trainingsprozess voraus: Das System analysiert hierbei eine große Anzahl an Beispielbildern. Dabei lernt es, die zu erkennenden Objekte aufgrund ihrer äußeren Eigenschaften eindeutig einer dedizierten Klasse zuzuordnen, sie also zu bestimmen. Herkömmliche Machine-Vision-Lösungen benötigen jedoch eine sehr hohe Anzahl von Trainingsbildern, um Gegenstände präzise zu klassifizieren und damit sicher zu identifizieren.
Für das Training der zu erkennenden Objekte müssen zudem deren distinktive Merkmale wie etwa Farbe, Form, Textur und Beschaffenheit der Oberfläche durch manuelle Programmierarbeit definiert werden. Dieser Prozess kann pro Objekt bis zu mehrere Wochen dauern und erfordert fundiertes Fachwissen. Viele Unternehmen können die damit verbundenen Kosten nicht stemmen.
Funktionen nutzen künstliche Intelligenz
Um hierbei den Aufwand zu minimieren und dennoch robuste Erkennungsraten zu gewährleisten, enthalten moderne Bildverarbeitungssysteme heute ausgefeilte Funktionen auf Basis künstlicher Intelligenz (KI). Damit lässt sich der gesamte Trainingsprozess stark vereinfachen und der Programmierbedarf signifikant reduzieren. Denn nur so können die Systeme mit der rasanten Weiterentwicklung der industriellen Fertigungsverfahren im Rahmen von Industrie 4.0 Schritt halten. Die großen Mengen an digitalen Bilddaten (Big Data), die durch die Bildeinzugsgeräte erzeugt werden, lassen sich dann mittels dieser KI-Verfahren detailliert auswerten. Eine große Bedeutung haben hierbei Technologien, die auf Deep-Learning-Algorithmen und Convolutional Neural Networks (CNNs) beruhen.
Im Gegensatz zu konventionellen Machine-Vision-Verfahren können diese Systeme durch die fundierte Analyse von bildbasierten Big Data eigenständig Objekte klassifizieren. Im Rahmen eines umfassenden Trainingsprozesses sind die Technologien in der Lage, spezifische Muster zu lernen, die typisch für bestimmte Merkmale sind. Dadurch lassen sich die jeweiligen Gegenstände zweifelsfrei einer entsprechenden Objektklasse zuweisen.
Das System analysiert hierbei vorkategorisierte Bilder, weist sie automatisiert einer bestimmten Klasse zu und prüft, ob diese „Vorhersage“ der tatsächlichen Kategorie entspricht. Dieser Vorgang wird solange wiederholt, bis ein optimales „Vorhersage“-Ergebnis erreicht ist. So werden Modelle (Klassifikatoren) trainiert, mit denen sich schließlich neu aufgenommene Bilder in die in diesem Training gelernten Klassen einordnen lassen.
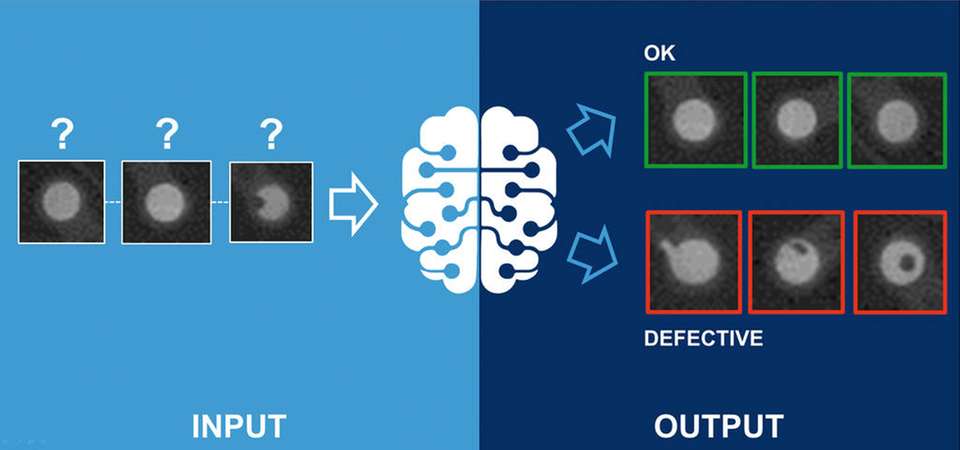
Der große Vorteil von Deep Learning zeigt sich insbesondere bei der Identifikation fehlerhafter Produkte: Aufgrund der Vielfalt potenzieller Mängel ist es meist kaum möglich, manuell valide Algorithmen zu entwickeln, die das gesamte Spektrum an denkbaren Fehlern erkennen können. Experten müssten dafür eine sechsstellige Anzahl von Bildern einzeln betrachten, analysieren und darauf basierend einen Algorithmus programmieren, der den entsprechenden Defekt möglichst detailliert beschreibt. Dieser Prozess verursacht erheblichen Aufwand und massive Kosten.
Defekte zuverlässig erkennen
Deep Learning kann nun die Prozesse der Fehlerinspektion signifikant vereinfachen: Eigenständig lernt die Technologie spezifische Fehlermerkmale, auf dessen Basis bestimmte Problemklassen identifiziert werden können. Durch die Verwendung von vortrainierten Deep-Learning-Netzen sind weitaus weniger Beispielbilder erforderlich. Mit lediglich 300 bis 500 Bildern pro Klasse lassen sich unterschiedlichste Arten von Fehlern gezielt trainieren und erkennen. Dieses Nachtrainieren dauert nur wenige Stunden und ermöglicht eine wesentlich höhere Identifikationsrate als bei manuell programmierten Fehlerklassen. Dadurch lässt sich auch die Fehlerquote deutlich verringern: Liegt diese bei der händischen Programmierung bei bis zu zehn Prozent, sinkt sie bei selbstlernenden Algorithmen auf nahezu Null.
Ohne Profiwissen trainieren
Nutzen Unternehmen vortrainierte Netze, können sie umfassend von den Vorteilen durch Deep Learning profitieren. MVTec zum Beispiel bietet hierfür mit der Bildverarbeitungs-Standardsoftware Halcon eine praktikable Lösung. Diese Software enthält fortschrittliche Funktionen, mit denen Unternehmen ohne großen Aufwand CNNs selbst trainieren können.
Die Lösung setzt sich aus zwei vortrainierten Netzen zusammen: Eines davon ist auf Geschwindigkeit, das andere auf höchste Erkennungsraten optimiert. So lassen sich neuronale Netze erstellen, die exakt auf die Anforderungen der Kunden zugeschnitten sind. Unternehmen können damit neue Bilddaten auf einfache Art klassifizieren und dadurch den Programmieraufwand deutlich vermindern. Zudem benötigen Anwender hierfür keinerlei KI-Profiwissen, denn sie können die Deep-Learning-Netze bereits mit Grundkenntnissen in Machine Vision „fertig“ trainieren.
Zum Vergleich: Nach Schätzungen von MVTec-Experten müsste ein Unternehmen mindestens zwölf Personenmonate investieren, um selbst ein entsprechend leistungsfähiges Netz zu entwickeln. Professionelle Anbieter von proprietärer Software auf der anderen Seite verfügen in den meisten Fällen bereits über die entsprechende Expertise und die erforderlichen Ressourcen.
MVTec beispielsweise betreibt ein Kompetenzzentrum, in dem Spezialisten vortrainierte Deep-Learning-Netze entwickeln. Diese Netze sind präzise auf die speziellen Anforderungen und Anwendungen der Kunden optimiert. Ein weiterer Vorteil: MVTec verfügt über einen Fundus von rund drei Millionen selbst erstellten, lizenzfreien Bildern mit industrienahen Motiven. Dadurch ist das Nutzungsrecht des Bildmaterials jederzeit gewährleistet.
Hochautomatisierte Produktionsprozesse
Moderne Machine-Vision-Lösungen sind mit umfassenden KI-basierten Technologien wie Deep Learning und CNNs ausgestattet. Nur dadurch lassen sich ausreichend hohe Erkennungsraten realisieren und damit die Anforderungen hochautomatisierter Produktionsprozesse im Rahmen von Industrie 4.0 problemlos erfüllen. Durch die Nutzung von vortrainierten neuronalen Netzen auf Basis selbstlernender Algorithmen benötigen Anwender nur wenige Beispielbilder und können so den Aufwand und die Kosten für das Training von CNNs deutlich reduzieren.









.jpg "AI, Quantum, Net Zero – Technologien, die sich auf alle Industrien auswirken werden")