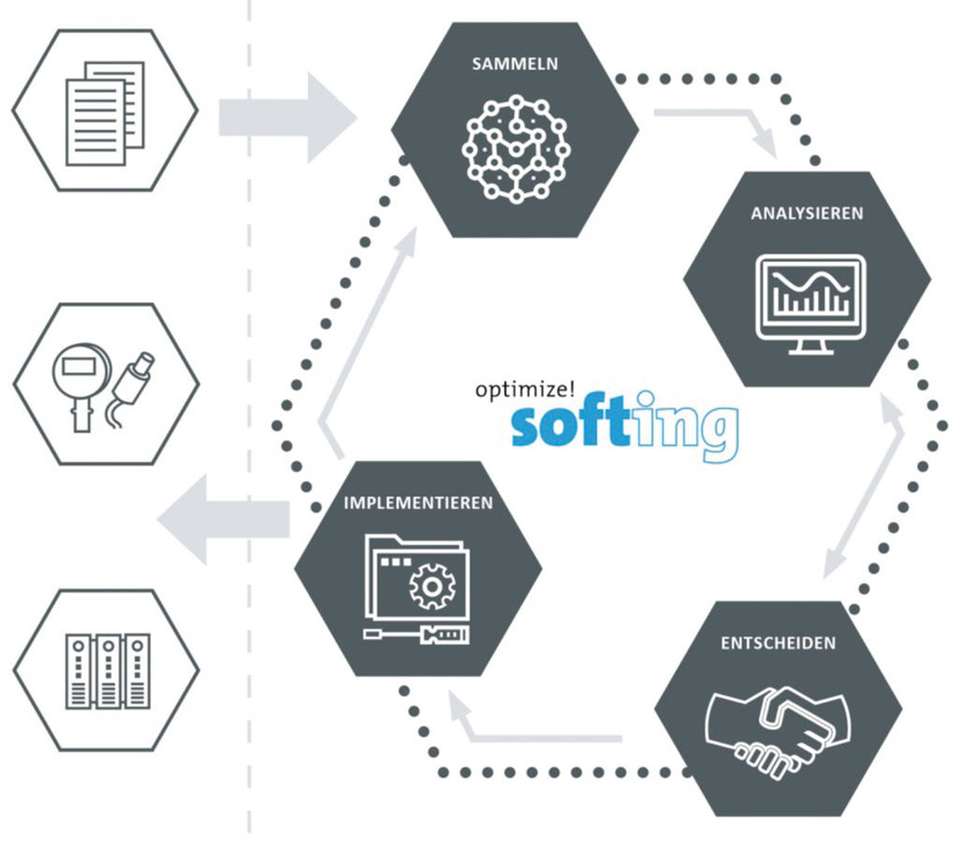
Alle Cloud- und IoT-Plattform-Anbieter haben mittlerweile eigene Datenanalyse-Lösungen in ihr Programm aufgenommen. Viele Entscheidungsträger haben aber ein mulmiges Gefühl bei der Idee, ihre Produktionsdaten nach draußen in die Cloud zu geben. Alternativ lässt sich mit einer Edge-Lösung, also in der Anlage beziehungsweise an der Maschine, an der die Daten anfallen, auf einem Standard-IPC das Sicherheitsrisiko reduzieren und die Gesamtanlageneffektivität – ein Produkt der drei Faktoren Verfügbarkeit, Leistung und Qualität – mittels industrieller Datenanalyse vor Ort verbessern.
Daten als wichtige Währung im 21. Jahrhundert
Daten sind das Öl des 21. Jahrhunderts. Zusätzlich zu Boden, Kapital und Arbeitskraft werden sie zunehmend zum Produktionsfaktor, ermöglichen Kosteneinsparungen und neue Geschäftsmodelle. Die zunehmende Herrschaft der Daten und die daraus resultierende Änderung der Reihenfolge von „Algorithmen -> Daten -> Entscheidungen“ zu „Daten -> Algorithmen -> Entscheidungen“ ist die Basis der gerade stattfindenden Revolution.
Seit dem ersten programmierbaren Chip – dem Intel 4004 aus dem Jahr 1971 – gehen Unternehmen bei der Entwicklung ihrer Software nach dem gleichen Schema vor: Sie definieren das Problem, bestimmen die zu erreichenden Ziele und legen die notwendigen Arbeitsschritte fest.
Schließlich schreiben sie die Anwendung als eine Reihenfolge von Algorithmen. In der Praxis werden den Algorithmen Daten gefüttert und Anwender treffen auf deren Basis Entscheidungen. Diese Vorgehensweise ändert sich momentan strukturell: im ersten Schritt werden die Daten gesammelt und im zweiten Schritt mittels allgemeingültiger Algorithmen analysiert. Auf Basis der daraus resultierenden Kausalitäten, trifft heute ein Mensch Entscheidungen zur Produktionsoptimierung; morgen übernehmen dies Algorithmen.
Computer und das maschinelle Lernen
Ohne Algorithmen des maschinellen Lernens würden heute wichtige Teile unserer Geschäfts- oder Konsumentenwelt stillstehen. Algorithmen entscheiden innerhalb von Millisekunden, ob ein Kunde am Automaten Geld ausbezahlt bekommt. Sie erkennen die Gesichter unserer Freunde in den sozialen Medien, lassen uns dem Smartphone Aufgaben stellen und regeln demnächst das autonome Fahren. Dieselben Algorithmen sagen uns, wie und wo wir unsere Produktion optimieren können, solange wir sie mit den dafür relevanten Daten füttern. Bei der Produktionsoptimierung geht es darum, auf Basis von Daten einer normal funktionierenden Maschine oder Anlage zu erkennen, was bisher nicht eingetroffen ist: nämlich ein Störungsfall.
Bereits 1959 definierte der US-amerikanische Informatiker und Computerpionier Arthur Samuel „machine learning” als ein Studiengebiet, welches „Computern die Fähigkeit gibt, zu lernen, ohne dazu vorher explizit programmiert zu sein“. Anders als bei klassischen Applikationen nimmt das maschinelle Lernen seine Lösung somit nicht direkt aus dem von Menschen geschriebenen Software-Code.
Vielmehr macht das Wesen des maschinellen Lernens aus, dass ein Muster existiert, welches wir nicht mathematisch festhalten können, aber welches durch Algorithmen auf Basis von Daten gefunden werden kann. Dabei kann man die Algorithmen mit Lösungskategorien füttern und den Algorithmus beauftragen zu entscheiden, welche Kategorie zukünftige Daten repräsentieren sollen („supervised learning“). Alternativ überlässt man es dem Algorithmus, selbst Muster oder Cluster zu finden, die dem Mensch bis dato nicht bekannt waren („unsupervised learning“).
Die Menge, Geschwindigkeit und Vielfältigkeit der heute anfallenden Daten übersteigt die Fähigkeiten des Bedienpersonals und verlangt nach neuen, datenbasierten Ansätzen. Vorausschauende Wartung zielt darauf ab, den großen Teil der nicht-altersbedingten Ausfälle zu reduzieren und somit die Anlagenleistung zu erhöhen. Algorithmen des maschinellen Lernens sagen den Ausfall konkreter Anlagenteile voraus. Das ermöglicht eine bedarfsgerechte Wartung spezifischer Teile zu produktionsfreien Zeiten, bevor es zum Ausfall kommt.
Datenbasierte Produktionsoptimierung vor Ort
Bei der klassischen Reihenfolge „Algorithmen -> Daten -> Entscheidungen” kann die Gesamtanlageneffektivität (GAE) nicht besser sein als der Mensch, der sie programmiert hat. Algorithmen des maschinellen Lernens, angewendet auf große Mengen Produktionsdaten, können dagegen Kausalitäten finden, welche die GAE verbessern und dem Anlagenbetreiber bis dato verborgen waren.
Eine Edge-Lösung direkt an der Maschine minimalisiert demnach das Thema Sicherheit und stellt eine alternative Möglichkeit dar, Produktionsdaten auszuwerten, ohne sie aus der Hand geben zu müssen. Das Ziel der gesamtheitlichen Verbesserung von Verfügbarkeit, Leistung und Qualität ist dabei nicht neu. Neu ist der datenbasierte Ansatz mittels maschineller Lern-Algorithmen; wenn gewollt in der Anlage.